
DeepSeek: China's ChatGPT-moment
Uit het departement: “Schokgolf ”

DeepSeek, een klein Chinees AI-lab, heeft zijn open-source redeneermodel R1 uitgebracht. Dat evenaart, of overtreft, naar verluidt OpenAI's o1 redeneermodel op bepaalde benchmarks, wat een verbazingwekkende prestatie is voor dit 2 jaar oude bedrijf. Maar er waren nog 2 andere redenen waarom deze prestatie de schokgolf veroorzaakte die we hebben gezien:
- DeepSeek zou de training van het R1-model hebben gedaan op inferieure AI-infrastructuur, omdat China door de VS is afgesneden wat betreft toegang tot geavanceerde AI-chips.
- DeepSeek's R1 model is beschikbaar voor commercieel gebruik en kost aanzienlijk minder dan o1 ($0,14 vs $7,5 per miljoen input tokens). Ook kost R1 slechts 5-10% van de API-prijs van o1 voor ontwikkelaars. Met andere woorden, de inferentiekosten (de kosten om het model te gebruiken) zijn aanzienlijk gedaald. Voor niet-commercieel gebruik wordt R1 gratis aangeboden (terwijl o1 bij OpenAI 300$ per maand kost). Bedankt DeepSeek.
Tot slot heeft DeepSeek hun R1-model open-sourced (vergelijkbaar met de aanpak van Meta met hun Llama LLM's) zodat iedereen er toegang toe heeft en erop kan voortbouwen. R1 is inderdaad beschikbaar op het AI-ontwikkelaarsplatform Hugging Face en is een van de best gedownloade modellen van de laatste tijd.
Heeft Nvidia problemen met DeepSeek?
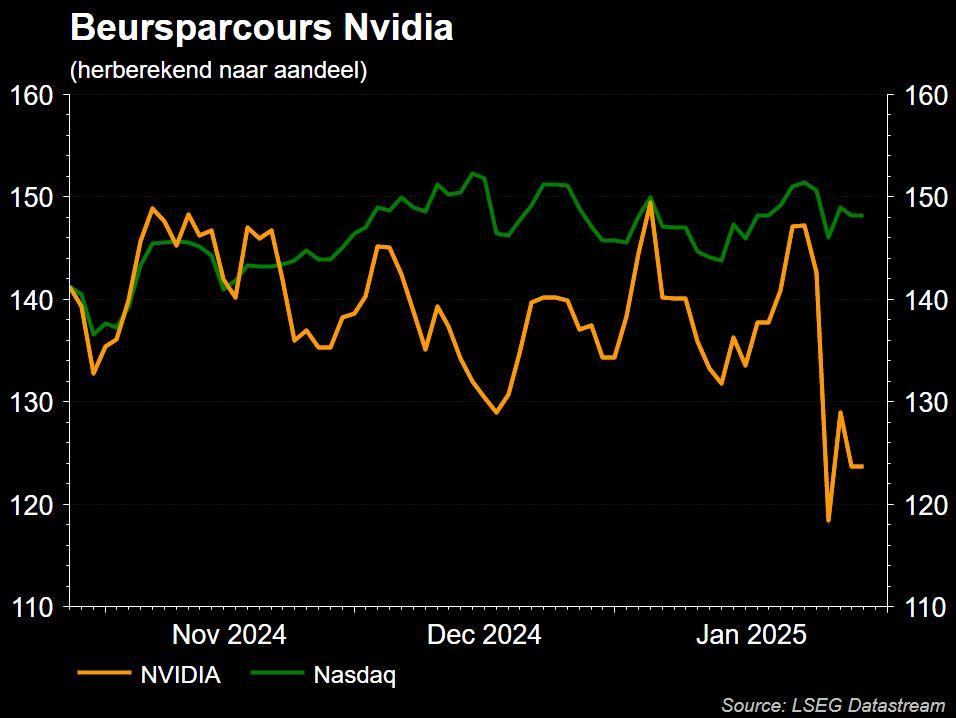
Sinds de lancering van ChatGPT in november 2022 zag Nvidia de vraag naar hun GPU-chips exploderen. De aandelenkoers van Nvidia steeg tot vandaag met meer dan 7x en het werd het meest (of een van de meest) waardevolle bedrijf ter wereld. Deze dramatische outperformance heeft geleid tot 'piekzorgen'. De vergelijking met de dot.com-zeepbel van 1999 wordt vaak genoemd. Daarom zijn beleggers sinds de zomer van 2024 erg nerveus geworden over de beleggingsthese van Nvidia, omdat ze vrezen dat de vraag naar Nvidia's AI-chips niet duurzaam is. Er zijn verschillende redenen gevonden om deze bear thesis te bewijzen:
- Er is momenteel nog steeds geen ROI (return on investment) voor de huidige mega-intensieve AI-infrastructuren.
- Schaalbare LLM's zien afnemende opbrengsten, dus op een gegeven moment zal er een limiet zijn aan het uitbreiden van de omvang van AI-infrastructuren.
- Nvidia heeft een monopolie op de AI-trainingsmarkt, maar niet op de AI-inferencingmarkt, die uiteindelijk veel groter zal worden dan de AI-trainingsmarkt.
- De overgang van Hopper naar Blackwell-chips zal leiden tot annuleringen van bestellingen voor de Hopper-chip.
- De nieuwe Blackwell-chip wordt geplaagd door oververhittingsproblemen.
- En nu kun je DeepSeek aan deze lijst toevoegen, want DeepSeek heeft aangetoond dat je helemaal geen dure AI-infrastructuur nodig hebt om geavanceerde AI-modellen te trainen.
De bezorgdheid over DeepSeek ging afgelopen weekend viraal op X (voorheen Twitter) en zorgde ervoor dat Nvidia-aandelen maandag 17% daalden, gevolgd door een bounce back van +9% op dinsdag. Deze daling van 17% is des te opmerkelijker gezien de context van
- Een enorme aankondiging van een Amerikaans Stargate-project van een investering van 500 miljard dollar in AI
- Meta's voorspelling van een versnelling van de investeringen naar 60 à 65 miljard dollar in 2025, slechts een paar dagen eerder.
OpenAI in de problemen met DeepSeek?
De perceptie dat DeepSeek met veel minder middelen kan wedijveren met de capaciteiten van OpenAI zou OpenAI onder druk kunnen zetten om zijn waardering van $157 miljard en uitgavenstrategie te rechtvaardigen. De opkomst van een sterke concurrent zou OpenAI's marktdominantie kunnen vertragen, wat een belangrijke factor is voor de hoge waardering. Bovendien veroorzaakt DeepSeek prijsdruk, wat de omzetgroei van OpenAI zal vertragen.
Er zijn ook aanwijzingen van een aanzienlijke braindrain bij OpenAI. Verschillende belangrijke hooggeplaatste werknemers hebben het bedrijf de afgelopen maanden verlaten. De braindrain lijkt te worden veroorzaakt door de verschuiving binnen OpenAI van non-profit (gericht op onderzoek) naar profit (gericht op productontwikkeling). Bovendien heeft DeepSeek bewezen dat OpenAI niet de enige is die erg innovatief is, wat waarschijnlijk niet helpt om de braindrain bij OpenAI te stoppen.
De VS in de problemen met DeepSeek?
Het is duidelijk dat de AI-wapenwedloop tussen de VS en China is toegenomen met de publicatie van het R1-model. Het is een wapenwedloop van groot belang gezien de bezorgdheid over nationale veiligheid, economische concurrentie en potentiële militaire toepassingen. Wie vooroploopt in AI, zal de wereld domineren...
Tot voor kort werd ervan uitgegaan dat de VS enkele jaren voor lag op China op het gebied van AI-ontwikkeling. De VS beperkten de toegang van China tot geavanceerde AI-chips van Nvidia om deze technologische voorsprong te behouden. Maar nu, dankzij DeepSeek, lijkt het erop dat China op gelijke hoogte staat met de VS, wat vragen oproept over de effectiviteit van al dat Amerikaanse beleid. En of dat beleid China misschien onbedoeld heeft gedwongen om creatiever te worden. "Noodzaak is inderdaad de moeder van alle uitvindingen." China is niet langer een na-aper. Denk ook aan China's suprematie in batterijtechnologie. Wat is het volgende gebied waar China technologisch leider wordt?
Opmerkelijk genoeg gaf China nog een goed getimede por aan de VS (toeval of expres?). De timing van de release van DeepSeeks R1-redeneringsmodel kwam tijdens de Amerikaanse presidentiële inauguratie van Donald Trump, vergelijkbaar met de lancering van Huawei's Mate 60 Pro 5G tijdens het bezoek van minister Raimondo aan China in 2023. Huawei zou nooit meer een toonaangevende smartphone kunnen maken.
En op het gebied van Chinese AI is DeepSeek in feite niet de enige Chinese "hoogvlieger". TikTok-moeder ByteDance en de Chinese internetgigant Alibaba hebben zeer recent ook LLM's uitgebracht die zich kunnen meten met de besten uit het Westen. Wederom een bewijs dat het plan van de VS om China's AI-ontwikkeling af te remmen helemaal niet heeft gewerkt.
Op het gebied van privacy heeft de VS ook te maken met een andere Chinese app die gericht is op de Amerikaanse consument. DeepSeek staat sinds enkele dagen op nummer 1 in de Amerikaanse App Store.
Jevons paradox
De paradox van Jevon (ook bekend als het Jevons-effect) is een economisch concept dat stelt dat wanneer technologische vooruitgang de efficiëntie van het gebruik van een hulpbron verhoogt, de totale consumptie van die hulpbron vaak toeneemt in plaats van afneemt. Dit gebeurt omdat:
- Verbeterde efficiëntie de hulpbron goedkoper maakt om te gebruiken
- Lagere kosten leiden tot een grotere vraag en nieuwe toepassingen
- De besparingen door efficiëntie worden vaak opnieuw geïnvesteerd in extra verbruik
Waarschijnlijk is deze paradox van Jevon ook van toepassing op AI. DeepSeek heeft LLM's gecommercialiseerd, de inferentiekosten zijn gedaald. En dit zal resulteren in een grote rugwind voor AI-adoptie. Uiteindelijk zal DeepSeek de vraag naar Nvidia's AI-chips ondersteunen. Maar waarschijnlijk zal DeepSeek nog beter nieuws blijken te zijn voor de softwaresector, omdat lagere inferentiekosten echt de aanzet zullen geven tot massale overstap naar AI!
Dieper ingaan op DeepSeek
DeepSeek is een Chinese AI-startup die zowel LLM's als redeneringsmodellen heeft ontwikkeld. Het bedrijf is voortgekomen uit High-Flyer, een Chinees kwantitatief hedgefonds dat in 2015 werd opgericht door Liang Wenfeng en AI gebruikte voor aandelenhandel. High-Flyer stootte zijn AI-onderzoekseenheid in 2023 af als DeepSeek, met de missie om AI te ontwikkelen voor het algemeen belang en de monopolisering van AI-technologie door een paar bedrijven te voorkomen. DeepSeek heeft 200 mensen in dienst (vergeleken met 3500 mensen bij OpenAI) die voornamelijk zijn gerekruteerd van de universiteiten van Beijing en Tsinghua.
DeepSeek heeft al twee indrukwekkende AI-modellen uitgebracht:
- Zijn LLM, v3, uitgebracht op 26 december 2024, is groter en geavanceerder dan veel westerse tegenhangers en heeft 685 miljard parameters.
- Het redeneermodel, R1, is uitgebracht op 20 januari 2025. Het is opmerkelijk dat OpenAI zijn eerste redeneringsmodel o1 op 5 december 2024 introduceerde, terwijl het op 12 september 2024 werd voorgepubliceerd (d.w.z. gepresenteerd, maar nog niet beschikbaar gesteld).
Volgens het technische rapport van DeepSeek verwerkte v3 14,8 biljoen tokens met behulp van 2,8 miljoen H800 GPU-uren, wat resulteerde in ongeveer $ 6 miljoen aan trainingskosten (tegen $ 2 per GPU-uur), waarbij 2048 "Hopper" H800 GPU's werden gebruikt. De H800 is het zwakke broertje van de H100. De prestaties ervan zijn met opzet beperkt door Nvidia om te voldoen aan de Amerikaanse exportbeperkingen naar China. Ter vergelijking:
- De trainingskosten van OpenAI's GPT4-model worden geschat op 63 tot 78 miljoen dollar.
- xAI's Grok 2-model werd getraind met behulp van ruwweg 20 miljoen H100 GPU-uren op 20.000 H100 GPU's.
- Het Grok-3 model (dat binnenkort wordt uitgebracht) is getraind op een cluster van 100.000 H100 GPU's.
Er is nogal wat scepsis rond de "$6 miljoen trainingskosten". Het zijn zeker niet de all-in kosten. En sommige mensen beweren zelfs dat DeepSeek 50.000 H100 GPU's heeft waarover ze niet kunnen praten vanwege de Amerikaanse exportcontroles.
Het R1-model bevat 671 miljard parameters, maar er zijn ook kleinere "gedistilleerde" versies, met slechts 1,5 miljard parameters, die lokaal op een laptop kunnen draaien. Het R1-model wordt geprezen om zijn innovatieve aanpak, die aangepaste communicatieschema's tussen GPU-chips omvat door het gebruik van MLA-technieken (Multi-head Latent Attention) en Mixture-of-Experts. Als gevolg van deze technieken was een minder krachtige AI-infrastructuur voldoende om dit model te trainen.